

Cloud Computing is Broken. Unikernels Can Fix it
An interview with Felipe Huici, CEO of Unikraft


TLDR: Cloud infrastructure relies on technology that was never intended to be reactive in millisecond scales, or at least within the round-trip time of a user request. Unikernels can directly address this, by running the app as close as possible to the hypervisor, thus avoiding running many wasteful and outdated layers of software. This makes code run two orders of magnitude faster than in containerized environments, drastically reduces scale to 0 and auto-scale times, and all but obliterates cold starts. For all their upsides, unikernels have a reputation for being hard to deploy, but no longer: on KraftCloud, unikernels meet Docker, marrying their incredible power with the amazing usability of Dockerfiles.
We sat down with Felipe Huici, the cofounder and CEO of Unikraft, to understand why Unikernels might change how developers go about cloud computing, and how his company is pioneering these new approaches. The interview has been edited for clarity.
Disclosure: one of the authors of this blog has invested in Unikraft.
What is broken about the cloud?
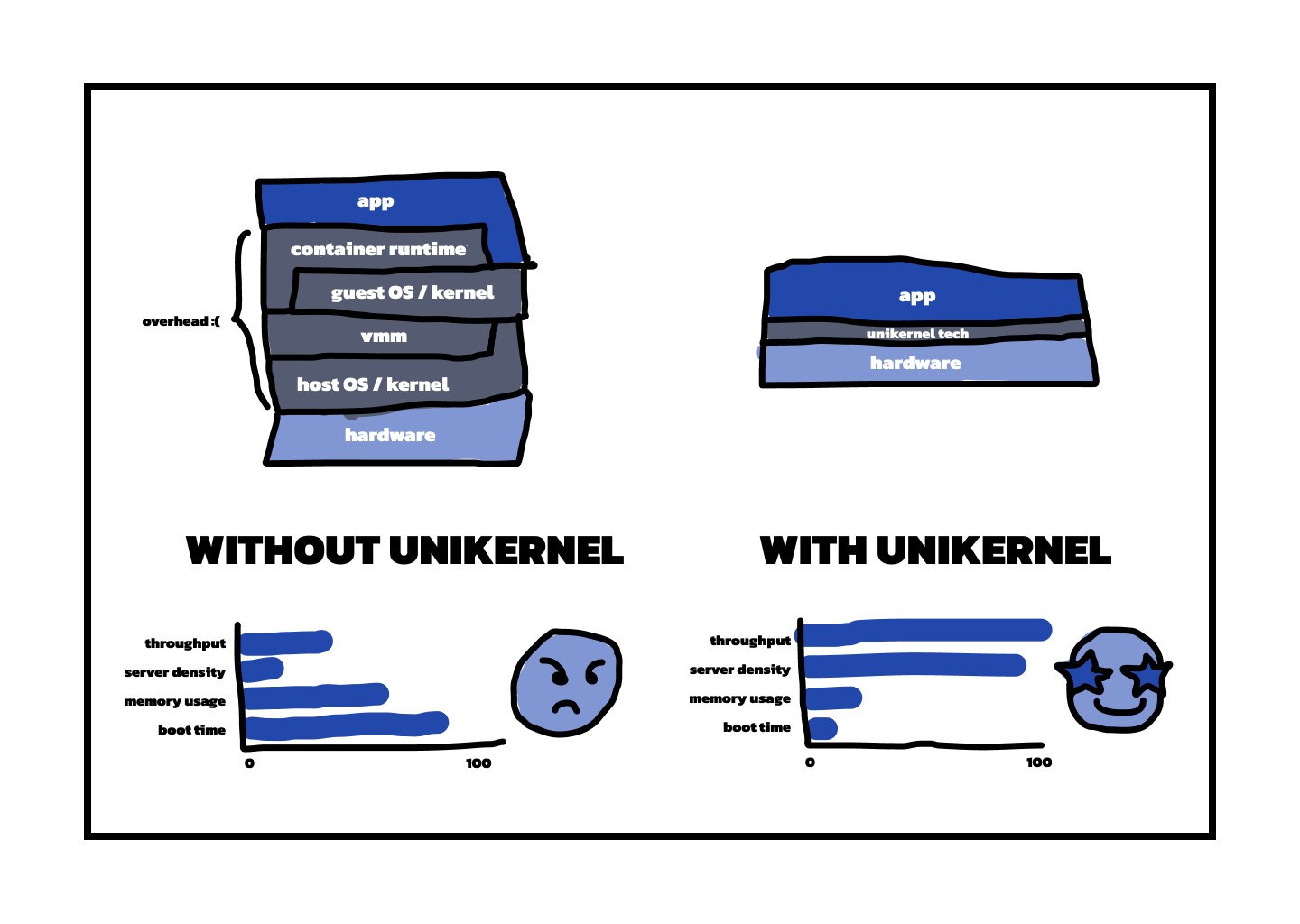
From a first principles perspective, you would like a cloud stack consisting of (1) the hypervisor, providing, strong, hardware-level isolation for multi-tenancy, and (2) your application, arguably the only part of the cloud stack you actually care about.
Instead, when you deploy an app on the cloud today you get a large number of layers between the hypervisor and the app, layers that have accreted over time. From the bottom up:
First comes the virtual machine, and the operating system/distribution it is based on. For functionality, ease of use and other reasons, we use general-purpose OSes like Linux or Windows, even though generally speaking we know the application we’d like to run. Such OSes come with a kernel/user-space divide, even though the hypervisor underneath already provides isolation —so a layer of overhead.
In user space we often use a container runtime, because containers are practical even if not necessary for actual deployment. So now we have yet another layer of overhead and isolation.
On top of this we may have language-level isolation from the likes of v8 or more recently wasm
And the peak of this Everest of layers is your app, sitting on a mountain of overhead that on the cloud you pay for, even though it doesn’t go directly to your bottom line.
To make matters worse, controllers on the cloud tend to be slow and act in scales of seconds or minutes, adding to this overhead.
The end result is that cloud engineers have to contort themselves to try to avoid, mitigate, or outright burn through money to address a large number of symptoms arising from the way the cloud stack has been built over time.
Take cold starts for example: a royal pain, where the way to “solve” them is to pay providers to always keep apps warm, or periodically ping apps to keep the warm — and pay providers again.
Or autoscale, which is supposedly a mechanism to transparently cope with traffic peaks, but takes so long to kick in (often minutes), that people have to over-provision for peak traffic — once again unnecessarily paying money for idle services.
Scale to zero is no better. Looking at a wide swathe of implementing across providers, the term has come to mean anything where (1) the platform can detect an app is idle and transparently scale it to 0 (sleep) and (2) the platform detects a new request arriving and transparently scales back to 1. The big catch though is that in current platforms the sleep happens in seconds or minutes, during which you’re once again paying for idle. And the wake up part takes once again seconds or minutes, and so your users definitely notice that your app was sleeping — not such a transparent mechanism after all.
Not to mention other issues like large memory consumption, image sizes and exploding cloud bills. And there’s little you can do about it, because many of the overheads are not in the app you control, but in the underlying cloud stack and controller you don’t.
All of these are the normal, emerging symptoms of how the cloud stack and controllers have been built over time. We think it’s time to redesign the way cloud platforms are built: just the thinnest possible layer to make the app run on top of the hypervisor, coupled with a massively scalable, millisecond-reactive controller, so that users never pay for idle again, cold starts are a thing of the past, and you have full control over optimizing your deployment because most of the overhead will reside in your app.
This thin layer between the app and the hypervisor, what’s the magic sauce?
A hypervisor requires a virtual machine to run on top, but before you think “bloated”, “heavyweight” or “resource-hungry”, VMs need not be so 😀 . In fact, if you could magically make is so that the VM has a super specialized OS and distro, only containing the lines of code needed to run the app and nothing more, then that VM could boot in milliseconds, consume little memory, and have a small TCB, among other things. Such an extremely specialized thing is called a unikernel, and it’s one of the main engines, along with a custom controller, powering our KraftCloud platform.
Our unikernels are based on the Linux Foundation OSS Unikraft project, which is based on three key principles: (1) the OS is fully modular, so we can easily pick and choose the components that go into images; (2) it is Linux-API compatible, so we don’t break applications or languages and (3) it tries, as much as possible, to integrate with major tooling.
On the last point, for instance, we’ve made it so that on KraftCloud you can specify your app and root filesystem via a Dockerfile, and, with a single CLI command, we (transparently) build a unikernel with that filesystem and launch it. So container-like experience at build time, unikernel speed at deployment time.
So what’s the end result?
On kraftcloud, you can run a simple command such as `kraft cloud deploy -p 443:8080`` which along with a Dockerfile, will cold start an app in milliseconds. For instance, an NGINX instance can cold start in 15-20 millis and a Nextjs one in 130ms, to give two examples. So you never have to worry about cold starts again, because on KraftCloud they’re so short that they’re almost negligible.
Even better: add a -0 flag to the deploy command, and now you’ve enabled millisecond scale to 0 for your app: the platform will monitor (every 500 millis by default) to see whether your app is receiving traffic, and if it’s not, can automatically put it to sleep — making sure you never pay for idle. Then, when traffic comes back, we’ll wake your app in milliseconds too (remember those fast cold starts?) so that your users think you’re always running even if you’re not.
Same thing for autoscale: if you get traffic bursts/peaks, we’ll horizontally scale you in milliseconds, and back down when the peak is over — austocale the way it should be.
In all we’re trying to provide a platform that has all the great properties of others, whether serverles, container, or VM-based, with hopefully none or few of their shortcomings. And also minimizing cloud stack overhead so that most cycles go to your app and so you’re in control of your performance (and billing too!).
You mentioned a special controller being another key component?
Yes, we had to build a custom controller from scratch. If we wanted millisecond cold starts we couldn’t have a controller in that fast path that would take seconds or longer to react. We also needed a very scalable controller: because our unikernels are small, it’s potentially posible for us to host thousands of them on a single server — and even more if scaled to 0. We couldn’t find anything that would fit the bill, and so we wrote one from scratch.
So what’s next for you?
KraftCloud is currently in closed beta (kraft.cloud/signup) so we’re busy onboarding users and deploying new features. For example, we’re working on very fast snapshotting, whereby we can not only put apps to sleep, but to do so while saving their state without having to rely on volumes. We also have very recently introduced support for compose files, so that you can very easily set up complex services and connect them together.
If you’re interested in what Unikraft are building, check out their website at https://unikraft.io/, KraftCloud’s website at https://kraft.cloud, and the OSS project at https://unikraft.org.
More exciting tech news
The largest software companies are becoming hardware companies, Doug OLaughlin writes in The Tech Monopolies Go Vertical. As Moore’s law is stopping and demand for computing power keeps growing exponentially, big tech giants see no choice but to invest in their own hardware instead of running their search machines and social media platforms on good old Intel (or Nvidia) chips. A thought-provoking piece.
A throwback from the good old days when Spaghetti Code was still a thing: As Kent Beck writes in Untangling Spaghetti: Debugging Non-Terminating Object Programs, multi-object infinite loops can be a big mess. They might not occur very often, but they’re finicky and if you’re not careful they might crash your machine. Inlining seems like a good technique to carefully think out code like this.
In an uplifting and frankly quite endearing piece, Max Read takes on the lighter side of the AI debate: What if, aside from bringing humanity to collective doom, AI could actually assist us in the funny, illogical, creative, unprofessional, unproductive and downright stupid posts that we all secretly enjoy writing and reading? The Shitposting Zone makes it clear that the time we still have left to use AI for such meaningless purposes might be counted, and that we should enjoy being humanly obtuse with AI assistance while we can.
And milliseconds scale to 0 and 1, https://packagemain.tech/p/millisecond-scale-to-zero-with-unikernels