

Death to tech debt?
Deep dive into AI-driven tech debt reduction approaches and remaining technical limitations.


This post might be too long for some email programs. Click on "View entire message" to view the entire post in your email app.
TLDR: Recent advancements in AI-driven code generation and LLM-based code processing/understanding are transforming the software development landscape. Engineering leaders are now exploring whether these cutting-edge technologies can effectively reduce technical debt, streamline codebases, and enhance developer productivity. Is AI the key to overcoming one of the most persistent challenges in tech?
We created this deep dive as part of a research process with a very experienced tech executive who wants to build a venture in the “AI will fix tech debt”-space. He is still looking for team members for his new venture - reach out if you are interested!

Defining technical debt
Technical debt, as defined by Gartner, is the accumulated work "owed" to an IT system due to shortcuts and sacrifices made during software development. These compromises are often necessary to meet delivery deadlines but can lead to deviations from the software's nonfunctional requirements, eventually impacting performance, scalability, and resilience.
Gartner also highlights that legacy applications, though based on outdated technologies, are often critical to day-to-day operations. When these systems fail, the consequences can be severe, posing challenges such as code complexity, high development costs, and the risk of security vulnerabilities, which can paralyze even the most innovative companies.
Technical debt can be intentionally generated when leaders prioritize quick progress over optimal performance, a "build now and fix later" mentality. This approach leads to significant costs and effort required to address these shortcuts in the future.
Unintentional technical debt arises from a lack of standards, skipping best practices, changing requirements, and unexpected interactions. Without consistent coding standards, developers may create inconsistent or suboptimal code. Ignoring best practices and dealing with evolving project requirements and unforeseen system interactions can lead to workarounds and patches that accumulate debt.
How bad is tech debt today?
The impact of tech debt can be broken down on two axes: On the one hand, it has operational and strategic consequences, such as more necessary maintenance, reduced developer productivity, and reduced agility. On the other hand, the monetary costs can be staggering, as exemplified by a survey by Stripe, which finds that out of a 41.1-hour average work week, the typical software developer spends 13.5 hours, or almost a third of their time, addressing technical debt.
Operational & strategic consequences of tech debt
Time-Consuming Fixes: Poorly written or complex code is harder to understand and modify, leading to more time spent on bug fixes and enhancements.
Frequent Bugs: Technical debt often results in a higher number of bugs, requiring ongoing maintenance efforts.
Reduced Developer Productivity
Complex Codebase: Developers spend more time trying to understand and navigate a messy codebase, which slows down their ability to implement new features.
Context Switching: The need to address technical debt issues frequently interrupts development work, reducing overall productivity.
System Performance
Performance Issues: Suboptimal code can lead to performance issues, affecting the end-user experience.
Agility
Slower Feature Development: Adding new features becomes slower and more difficult as developers must work around existing debt.
Reduced Flexibility: The ability to pivot or adapt to new requirements or technologies is hindered by the need to constantly manage debt.
System Failure Risk
System Outages: Poorly maintained systems are more prone to outages and failures, which can be costly and damaging to the organization’s reputation.
Security Vulnerabilities: Technical debt can introduce security risks if shortcuts were taken in implementing secure coding practices.
Costs created by tech debt
IT Budget Impact:
Technical debt in legacy applications consumes substantial portions of a company’s IT budget and schedule, limiting the ability to create new features and capabilities.
In a survey of C-level corporate executives, 70% of respondents said that technical debt severely restricts their IT operation’s ability to innovate.
‘Principal’ on Technical Debt:
The cost to clean up or replace substandard code and modernize applications.
Research indicates that companies typically incur $361,000 of technical debt for every 100,000 lines of code in their software.
Like financial debt, the principal must be paid off eventually, and until then, the organization incurs ongoing interest.
‘Interest’ on Technical Debt:
Ongoing costs to maintain flawed, inflexible, and outdated legacy applications as the technological context evolves.
U.S. companies spend $85 billion annually on maintaining bad technology.
Impact of AI on Technical Debt:
The rise of generative AI may further increase technical debt.
New AI-generated code integrated into existing systems may introduce additional complexity and require ongoing maintenance.
Conventional approaches to tech debt reduction
To get rid of tech debt, developers use direct and indirect approaches. Direct approaches include refactoring, rehosting, and modularizing. Indirect approaches include code reviews, documentation, and prioritization. In practice, a combination of different approaches is typically used.
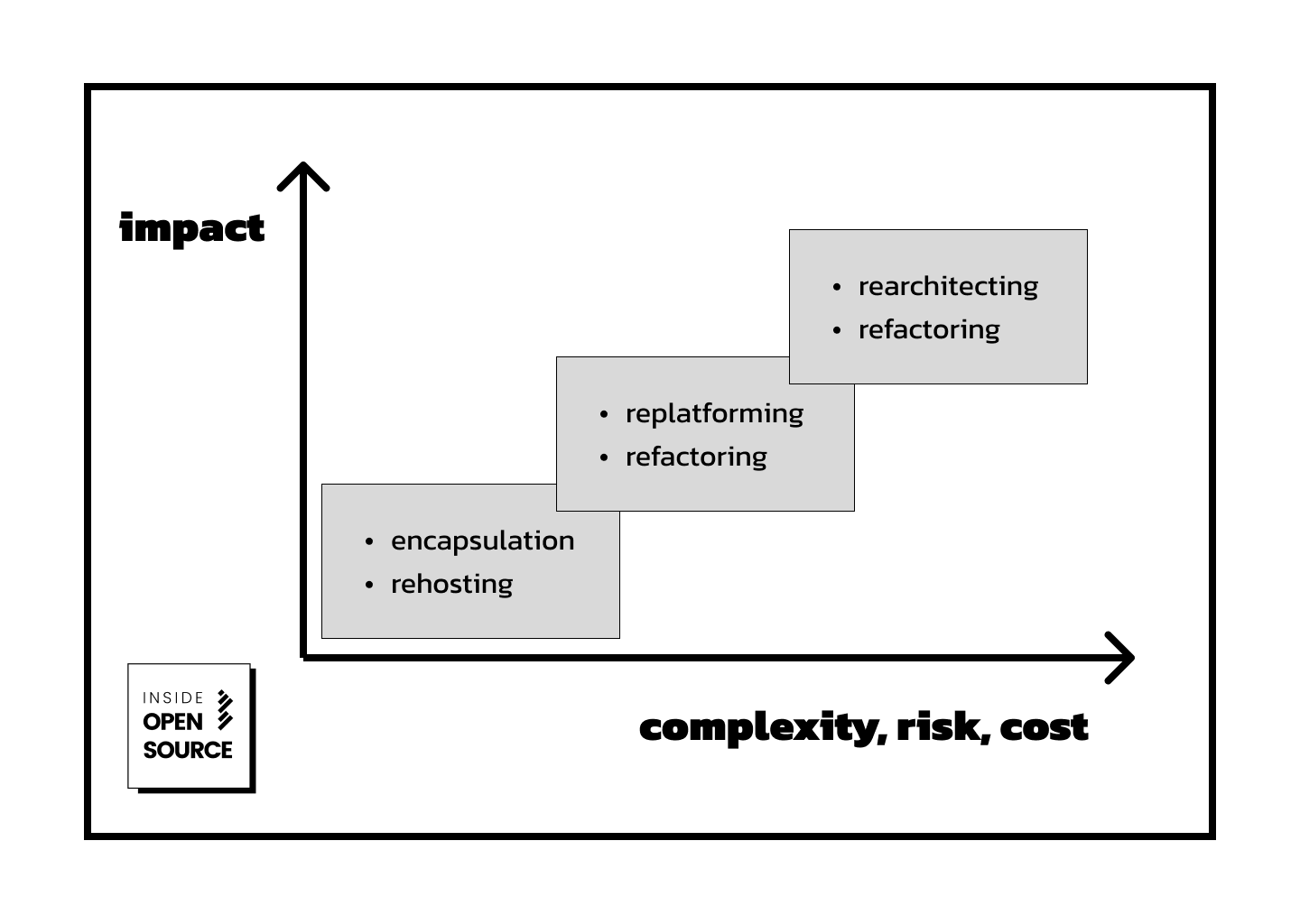
Direct approaches
Encapsulation
Description: Isolating legacy code by wrapping it with a modern interface.
Approach: Create a façade or API around old components, allowing new code to interact with them without directly depending on the legacy codebase.
Encapsulation can be a short-term solution that improves User Experience by enabling quick and effective use of legacy system data and functions.
Among the advantages of encapsulation, the relatively low cost of using this solution and the low risk are most often mentioned.
The main disadvantage of this approach is the fact that the costs incurred so far, related to the maintenance of the old system do not change, because no modifications have been made to the software itself and it is necessary to maintain its stability, as has been the case so far.
This approach is sometimes used when a company plans to implement new software that will partly use data or functions of the legacy system, but no expenditure is planned to modernize the old system to integrate it with the new one.
Refactoring
Description: Improving the internal structure of the code without changing its external behavior.
Approach: Regularly scheduled refactoring sessions to clean up code, reduce complexity, and improve readability and maintainability.
Rehosting
Description: Moving applications to a new environment (e.g., cloud) without significant changes to their architecture or code.
Approach: Lift-and-shift method to rehost applications, which can provide immediate benefits such as reduced infrastructure costs and improved scalability.
Replatforming
Description: Making minimal changes to an application to run on a new platform (e.g., changing the database or operating system).
Approach: Modify certain parts of the application to take advantage of new platform features without extensive rework.
Rearchitecting
Description: Restructuring the application’s architecture to improve scalability, performance, and manageability.
Approach: Break down monolithic applications into microservices or modular components, redesign the data flow, and adopt new architectural patterns.
Rebuilding
Description: Redesigning and coding the application from scratch while keeping the same functionality.
Approach: Start with a fresh codebase, use modern development practices and tools, and migrate data and functionality incrementally.
Replacing
Description: Completely replacing an old system with a new one.
Approach: Develop or acquire a new system, migrate data, and deprecate the old system once the new one is fully operational.
Modularization
Description: Breaking down large codebases into smaller, more manageable modules.
Approach: Identify cohesive units within the code and separate them into independent modules, making it easier to maintain and scale.
Incremental Modernization
Description: Gradually updating parts of the system while continuing to use the rest.
Approach: Implement changes in small increments, validate each change, and then proceed to the next, ensuring stability and continuous improvement.
Indirect approaches
Prioritization
Description: Regularly assess and prioritize technical debt items in the project backlog to ensure they are addressed systematically.
Approach: Use metrics such as impact on performance, frequency of related bugs, and developer productivity to prioritize which debts to tackle first.
Automated Testing
Description: Implementing automated tests to ensure code changes do not introduce new bugs.
Approach: Use unit tests, integration tests, and end-to-end tests as part of the CI/CD pipeline to catch issues early and improve code quality.
Documentation
Description: Maintaining comprehensive and up-to-date documentation.
Approach: Document code, architecture, and processes to help developers understand the system and reduce onboarding time for new team members.
Code Reviews
Description: Implementing a thorough code review process to ensure quality and consistency.
Approach: Use peer reviews to catch potential issues, share knowledge, and maintain coding standards.
Technical Debt Backlog
Description: Keeping a separate backlog for technical debt items to ensure they are tracked and managed alongside feature development.
Approach: Regularly review and prioritize the technical debt backlog to address the most critical issues first.
Why most modernization projects fail
According to one study, the average app modernization project costs $1.5 million and takes about 16 months to complete. And after all that investment of time and resources, 79% of those projects fail. Speaking of companies that have not had the success they hoped for with their application modernization efforts.
McKinsey reports that: “In our experience, this poor performance is a result of companies’ uncertainty about where to start or how to prioritize their tech-debt efforts. They spend significant amounts of money on modernizing applications that aren’t major contributors to tech debt, for example, or try to modernize applications in ways that won’t actually reduce tech debt.”
Reducing tech debt with AI
Traditional methods like refactoring, code reviews, and manual testing have long been the go-to strategies for managing technical debt. However, generative AI presents a paradigm shift in code management by leveraging machine learning algorithms to automate various aspects of technical debt management.
One significant advantage of AI is its ability to monitor systems that analyze code changes, identify potential issues, and provide early warnings about technical debt accumulation. Tools like Code Climate offer automated code reviews that help identify and fix technical debt early on, monitoring problem areas in the codebase such as duplicate code.
AI can also suggest optimal refactoring strategies by analyzing code patterns and proposing changes to enhance code readability, maintainability, and performance. This level of automation ensures that the codebase remains clean and efficient, reducing the burden of technical debt.
Moreover, AI can prioritize workflows by predicting which areas of the codebase are most likely to develop technical debt, allowing development teams to address critical issues first.
Generative AI can also automate code documentation generation, a time-consuming task in software development. Tools like OpenAI's Codex analyze the codebase and generate comprehensive documentation for functions, classes, and modules, ensuring that documentation is accurate and up-to-date.
Automated testing is another area where AI excels, helping to ensure that new code does not introduce additional technical debt. When it's time for system migration, AI can analyze legacy systems to identify areas where technical debt can be reduced. For example, tools like CodeClone can detect redundant code snippets across a project and suggest consolidation or removal, while Simian identifies and helps eliminate duplicate code.
AI also aids in task prioritization by identifying critical technical debt issues that need immediate attention, allowing developers to address them quickly.
Deployment automation generated by AI reduces technical debt while standardizing and streamlining code changes throughout the software development lifecycle.
By incorporating these AI-driven tools and techniques, engineering leaders can effectively manage and reduce technical debt, paving the way for more innovative and agile development practices.
The AI tech debt market
AI tech debt solutions on the market are diverse and specialized. Generic LLMs, which can generate code among other capabilities, and code-gen-specific LLMs are prominent tools and can be used by developers to address tech debt.
Next to those agnostic platforms, there are a bunch of point solutions that address tech debt reduction via one of approaches outlined above.
We created a comprehensive but surely non-exhaustive list of companies offering either agnostic platforms to reduce tech debt with AI. We clustered the point solutions like this (beware consultants of this world: not MECE):
AI Migration Tools
AI Refactoring, Debugging & Code Cleaning
AI Code Analysis
Code Review & Documentation
AI Testing

Remaining technical challenges for AI-driven tech debt reduction
SWEBench evaluations have revealed most base models can only fix 4% of issues, SWE-Agent can achieve 12%, Cognition reportedly 14%, OpenDevin up to 21%. This is still pretty low if you want to touch production code, and is due to a number of issues.
AI code refactoring performance is bad
CodeScene, led by Adam Tornhill, conducted a comprehensive benchmarking study using large language models (LLMs) from OpenAI, Google, Meta, and others to refactor code. The results were underwhelming: 30% of the time, the AI failed to improve the code, and in two-thirds of the cases, the AI broke the unit tests, subtly but critically altering the code’s external behavior. The best-performing AI correctly refactored code just 37% of the time, while the rest either got it wrong or didn’t enhance the code at all.
The study, which involved a data lake of over 100,000 examples of poor code and corresponding unit tests, revealed significant issues with AI's code refactoring capabilities. While AIs could rewrite code in a different way, they often failed to improve code health or maintain correctness. Tornhill noted that these models tend to break down, particularly with legacy codebases featuring extremely long functions or deep nesting, highlighting the limitations of LLMs in understanding and accurately refactoring complex code structures.
Furthermore, the study found that AI models struggle with certain code patterns that are challenging for human programmers as well. Constructs like continuous statements inside deep loops posed significant difficulties for the AI, suggesting that while LLMs can handle simpler refactoring tasks, they falter with more intricate code scenarios.
CodeScene's research also explored whether using models operating at the level of the abstract syntax tree (AST) rather than raw code text could improve performance. Preliminary findings indicated that AST-based models performed better, particularly in understanding and refactoring across different programming languages within the same family or paradigm. However, these advancements have not yet been fully published, and significant challenges remain in guaranteeing that AI-refactored code is semantically equivalent to its original state.
Remaining challenges
Current and Next Gen Context Windows are Too Small for Large Code Bases
Current LLMs offer context windows of varying sizes: GPT-4 has a 128K context window, Claude 3 extends to 300K, and the latest Gemini model boasts 2M tokens. However, these windows are still insufficient for large codebases. The size of a codebase, in terms of tokens, varies significantly based on project complexity. For instance, an average iPhone app may have less than 50,000 lines of code, while a modern car uses around 10 million lines, and the Android operating system comprises 12-15 million lines of code. Google's entire codebase exceeds 2 billion lines of code. For a 50,000-line iPhone app, approximately 625,000 tokens are needed, exceeding the context window of even the best current LLM for code (GPT-4).
Larger Context Windows Come with New Challenges
While expanding context windows can help, it introduces new challenges. The quality of responses may degrade, as LLMs tend to focus more on the beginning and end of content, as evidenced by the "Lost in the Middle" research. Additionally, the cost and time to compute increase exponentially due to a quadratic relationship between context window size and inference cost. Optimizing this relationship to a linear one is an area of active research, but current costs and computation times remain prohibitive for very large context windows.
Almost Infinite Context Windows: Cost and Efficiency Issues
Google's recent experiment involved tying together 512 Nvidia H100 GPUs to create an "infinite" context window capable of managing 10M+ token-long requests. Despite optimizing the configuration, it takes about 50 seconds to process a 10M token request, costing approximately $17 per inference. This high cost and time requirement make such solutions impractical for most applications, emphasizing the need for more efficient approaches.
Modularity is Key to Making LLMs Work with Large Code
The size of most code projects exceeds the working context windows of both humans and machines. However, humans have the advantage of thinking modularly, focusing on APIs and ignoring intricate details. Embracing modularity can help LLMs function more effectively with large codebases. GitHub Copilot, for example, uses classifiers to determine which parts of the code to process, ensuring quick and relevant suggestions. This approach allows for efficient code completion and unit test generation without requiring an extensive context window.
Context-Aware Retrieval-Augmented Generation (RAG) Could Make It Work
The key challenge is accessing necessary information and context outside the open file, which cannot be solved by merely increasing the context window size. Context-aware RAG presents a promising solution by retrieving relevant code snippets from various parts of the codebase and even external sources. This method, used by startups like Codeium, improves context by crawling imports, directory structures, and considering user intent. Advanced retrieval logic and fine-tuning can significantly enhance the accuracy and efficiency of LLMs in handling large codebases, offering a competitive edge for startups specializing in this area.
Summary and Outlook
The ever-evolving landscape of software development faces persistent challenges posed by technical debt, which arises from shortcuts and compromises made during the coding process. This debt accumulates over time, affecting maintenance, developer productivity, system performance, agility, and increasing the risk of system failures and security vulnerabilities. The rising complexity and size of modern codebases further exacerbate these issues, making it crucial for organizations to find effective ways to manage and reduce technical debt.
Recent advancements in AI-driven code generation and refactoring tools offer promising solutions to tackle technical debt. Generic large language models (LLMs) and code-gen-specific LLMs, along with specialized point solutions such as codebase maintenance companies, code documentation tools, legacy code conversion services, and AI-driven architectural observability platforms, provide targeted approaches to improve code quality and maintainability. However, these tools also face limitations, particularly in handling large and complex codebases.
Studies conducted by companies like CodeScene reveal that current AI tools often fail to refactor code correctly, with LLMs breaking unit tests and altering code behavior in unintended ways. The limitations of context windows in LLMs, even in advanced models like GPT-4, Claude 3, and Gemini, hinder their ability to process large codebases effectively. Despite the availability of context windows up to 2M tokens, typical projects like a basic iPhone app with 50,000 lines of code can exceed these capacities, demonstrating the need for more efficient approaches.
Expanding context windows introduces new challenges, including quality degradation and increased computational costs, as seen with Google's experiment involving 512 Nvidia H100 GPUs. These solutions, while powerful, are impractical for widespread use due to their high cost and processing time. Therefore, embracing modularity in coding and leveraging context-aware retrieval-augmented generation (RAG) methods present viable alternatives.
The outlook for AI-driven solutions in managing technical debt is promising but requires continuous refinement. Enhancements in modularity, context-aware retrieval, and the integration of abstract syntax tree (AST) models are critical for improving AI's performance with large codebases. Startups and established companies alike are investing in these innovations, aiming to create more reliable and efficient tools for reducing technical debt.
In conclusion, while AI technologies have made significant strides in addressing technical debt, they are not yet a comprehensive solution. The collaboration between AI capabilities and human expertise remains essential in overcoming the complexities of modern software development. By focusing on modularity, improving retrieval methods, and refining AI models, the industry can advance towards more sustainable and agile development practices, ultimately enhancing productivity and innovation in the tech sector.